Summary of Technical Skills:
Programming:
- Proficient: Python, R, SQL
- Familiar: Java, C, MATLAB
Libraries:
- Scikit-Learn, XGBoost, Pandas, Pytorch, PySpark
Tools:
- Power BI, Cloud Computing (AWS, Databricks, IBM Studio Watson)
Familiar means that I did a few projects/scripts with that language/tool
Supervised Learning
Tabular and Text Data

Image taken from http://www.byteplusone.com/mulesoft-working-with-csv-files/
Sparkify Customer Churn
Predicted customer churn for a digital music service. Churn was defined as downgrading from premium to free tier or cancelling the service. Project was done with PySpark. The code was tested on my local machine with a 125 mb dataset, on IBM Studio Watson and Databricks with a 237 mb dataset, and on AWS EMR with the full 12 gb dataset.
| Code | Blog |
Starbucks Promotional Strategy with Uplift Models
Explored data from Starbucks Rewards Mobile App and implemented a promotional strategy with uplift models. Data contains 4 demographics attributes of customers and as well as timestamped customers’ transactions performed on the app. Due to the low number of features available, substantial feature engineering were done. Also predicted missing demographics attributes with machine learning models. Used classification models to predict customers’ probabilities of profits in 2 situations: 1) given promotions, 2) not given promotions. Difference in the two probabilities is the uplift value, and promotions will be sent to individuals with positive uplift values. Measured profitability of the promotional strategy using Net Incremental Revenue (NIR). Found promotional strategies with positive NIR for 6 out of 10 types of promotions. This was also the capstone project for my Udacity DSND course.
Wrote about the project on a Medium blog post that was published on Towards Data Science.
| Code | Blog |
Classify Messages with Pipelines
Build basic ETL and ML pipelines to classify messages that were sent during disasters, using data from Figure Eight. Deployed model on a simple web app.
Airbnb Data Science Blog Post
Explored Boston Airbnb Open Data and the Seattle Airbnb Open Data from Kaggle: Boston, Seattle. Investigate what features of Airbnb properties in those areas were correlated with higher rental revenues. Also answered the following questions:
- How much revenue do Airbnb hosts make?
- What are the best types of property to rent?
- When is the best time to rent?
- Which are the best areas to rent?
- What should you write in a listing name to attract more attention?
Shared the results on a Medium blog post that was published on Towards Data Science.
| Code | Blog |
Starbucks Portfolio Exercise
Implemented 4 different types of uplift models to identify customers whom we should send promotions. These models will help identify customers who will purchase products only when given promotions. This will reduce promotional costs, as we will refrain from sending promotions to customers who will puchase products regardless of being given promotions. Shared the results on a Medium blog post published on Data Driven Investor.
| Code | Blog |
Predict Future Sales
Project for the Predict Future Sales competition at Kaggle. Currently obtained a test RMSE score of 0.92212 (top 24% of leaderboard), as of 18 January 2019.
Finding Donor
Used several machine learning algorithms to predict individuals’ income with data collected from the 1994 U.S. Census.
Classify Fake News
Implemented Naive Bayes classifier from scratch with just numpy, a Logistic Regression algorithm with Pytorch, a MLP Neural Network with Pytorch, and a Decision Tree Classifier with Scikit-Learn. Used these classifiers to predict whether a news headline is real or fake news. Code from this project was split in two sections.
The first section includes the Naive Bayes, Logistic Regression and Decision Tree algorithms:
| Code | Report |
The second section includes the MLP Neural Network Algorithm:
| Code | Report |
Image Data
 Image taken from https://www.gettyimages.ca/
Image taken from https://www.gettyimages.ca/
Image Classifier Python Application with Transfer Learning
Implemented an image classifier with Pytorch. The project can be run from the command-line as a python application. The application offers a variety of pre-trained architectures (AlexNet, VGG, Resnet, DenseNet) to extract features from the input images. the script will then train the fully-connected layers of the classifier.
Facial and Handwritten Digits Classifier with Neural Networks
Built systems for handwritten digit recognition and face recognition. The systems were based on several neural network arhcitectures:
- Single layer neural network implemented from scratch with just numpy
- Single hidden layer neural network implemented with Pytorch
- Transfer-learning model using a pre-trained AlexNet CNN to extract features from images and training only the final fully-connected layers. Implemented with Pytorch.
Used face images from FaceScrub and the MNIST digits dataset to train and test the system.
| Code | Report |
Facial Classifier with Linear Regression
Built a face recognition and gender classification system. The system was based on a linear regression algorithm implemented from scratch with just numpy. Images of actors and actresses from FaceScrub will be used to train and test our system. The system includes a script that will download and process the images from a url text file.
| Code | Report |
Unsupervised Learning
 Image taken from https://www.geeksforgeeks.org/clustering-in-machine-learning/
Image taken from https://www.geeksforgeeks.org/clustering-in-machine-learning/
Bertelsmann Segmentation Analysis
Worked with data provided by Bertelsmann Arvato, which contained 85 demographics attributes from 191,652 customers and 891,211 individuals from the German population. Applied unsupervised learning techniques (K-Means) to identify segments of the German population that were popular or less popular with a mail-order firm, a client firm of Bertelsmann. Identified differences in demographics attributes between the firm’s most popular and least popular customers.
Recommendation Systems
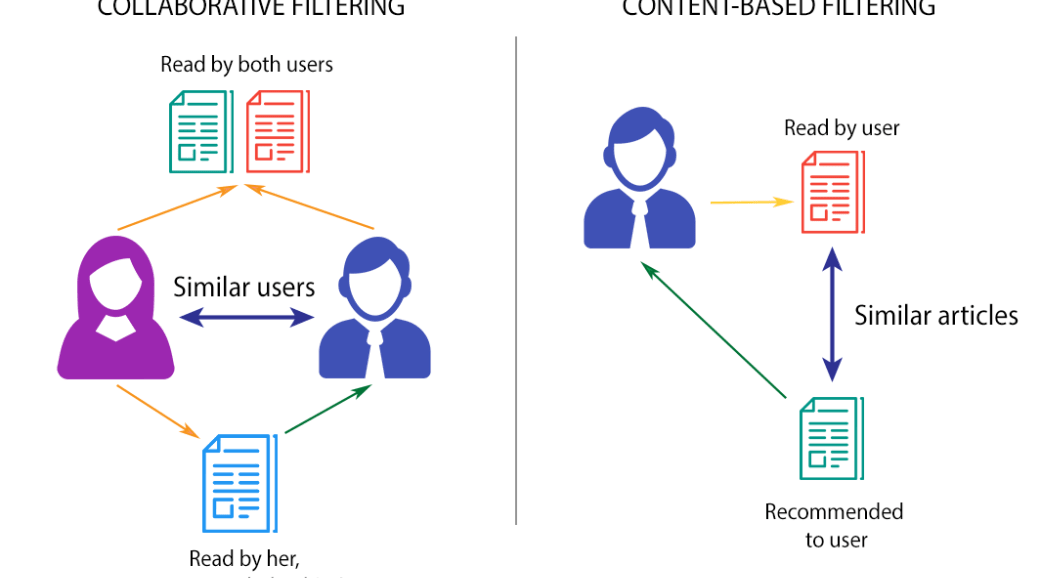 Image taken from http://datameetsmedia.com/an-overview-of-recommendation-systems/
Image taken from http://datameetsmedia.com/an-overview-of-recommendation-systems/
IBM Recommendation Systems
This project explored several algorithms used in recommendation engines. Recommended articles for users on the IBM Watson Studio platform using the following techniques:
- Rank-Based Recommendations: Recommended most popular articles based on the highest user interactions
- User-User Based Collaborative Filtering: Made a more personal recommendation to a user by recommending unseen articles that were viewed by similar users
- Content Based Recommendations: Recommend articles that were similar in content to a given article. Converted article headlines and descriptions to TFIDF vectors, reduced the vectors’ dimensions with PCA, then find closest articles based on euclidean distances.
- Matrix Factorization: Use SVD to find new articles that a user will like to read
Reinforcement Learning
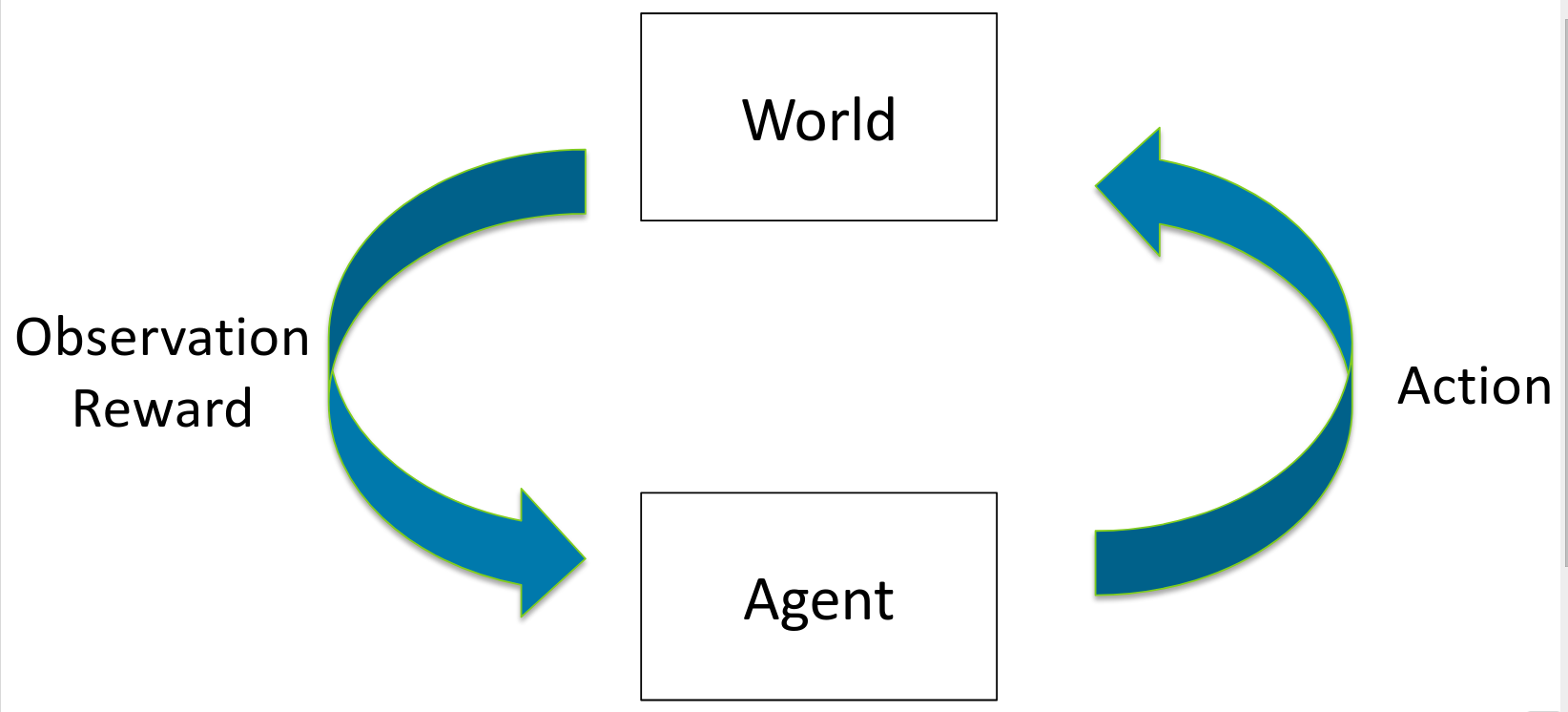 Image taken from http://web.stanford.edu/class/cs234/index.html
Image taken from http://web.stanford.edu/class/cs234/index.html
Tic-Tac-Toe Playing Agent
Implemented policy gradient to train an agent to play Tic-Tac-Toe.
Part 1 of the project involved training the agent against a random computer opponent:
| Code | Report |
Part 2 of the project involved training the agent against itself:
| Code | Report |